Guidebook - Overview
What does Antelope do ??
Antelope structures your life cycle inventory model as a collection of “fragments”, which represent exchanges of material flows that can be observed in real life. [flows elsewhere] Each fragment represents a material flow that occurs in the system being modeled.
These fragments are linked together to form tree structures, called “spanners” (as in spanning tree). Each spanner is defined by its reference flow.
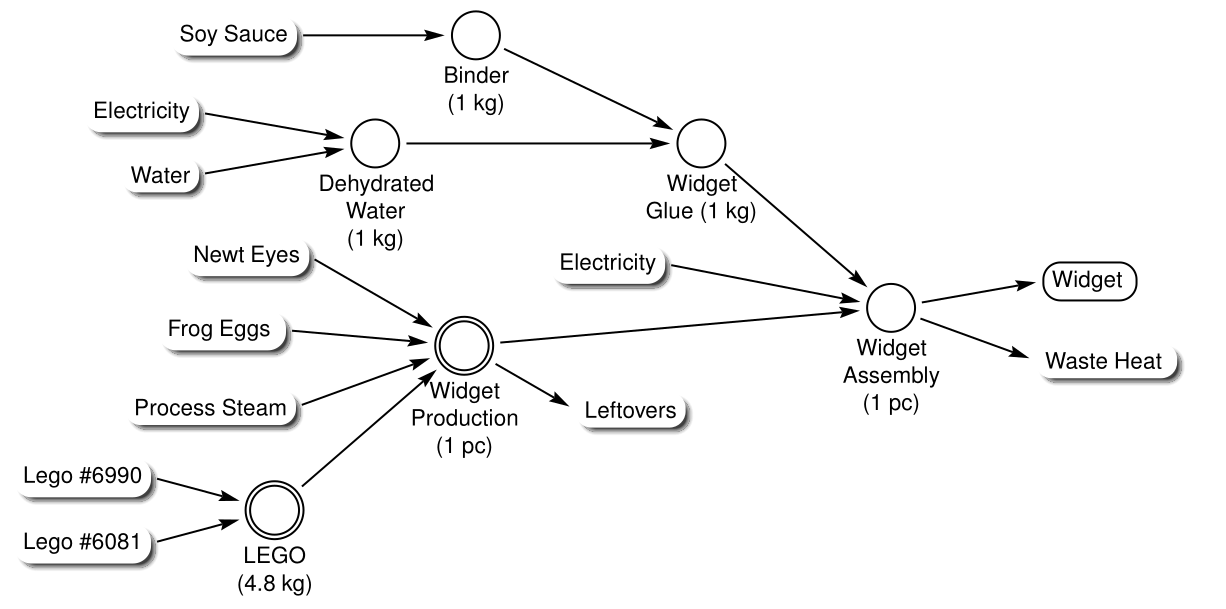
A spanner is a formal definition of a gate-to-gate LCA system, in the sense that every node is in the system boundary, and everything that is not an observed flow is not in the system. Two practitioners can look at the model and agree on what’s in it.
These spanners form the modeling elements of the Antelope environment, and they can be linked together, shared, and reused.
Structuring the model
The task of modeling is itself irreducible- it must be performed by a person (or some other agent) who is familiar with the system. The graph structure of the spanner records that work.
If the flow is a material, say a product that a factory is shipping, the modeler can trace it physically along its journey through the facility, observing what happens to it in reverse order. As long as the modeler can obtain credible information about individual exchanges, the observed exchanges are part of the model “foreground.” As soon as a flow is no longer observable, it leaves the foreground system boundary and enters the “background.” This does not necessarily mean the flow goes “far away”- it simply is no longer being observed.
The modeler can take advantage of selective observation to design re-usable models. Any flow whose target is not observed becomes a “cutoff.” Cutoff flows can be linked later on during modeling to nodes that haven’t yet been specified. If a modeler embeds one spanner as a subcomponent of a larger models, then the cutoff flows can get linked to exchanges contained in that larger model. Thus the same spanner can generate different life cycle models by being re-used in different contexts.
Take truck transportation. It is very common for LCA modelers to make use of background data sources like USLCI or ecoinvent for modeling transportation, and then reflexively consider transportation (especially if it is operated by the client, e.g. “Scope 1”) to be part of the model “foreground”, but this is not entirely correct. Using our observation framework, we can understand that the foreground is limited to what the modeler observes, which in this case is most likely the transportation services used (mass or volume of goods, distance traveled, maybe the type or size of equipment). These are foreground parameters. The emissions data are assuredly not being observed and these remain in the background.
The modeler can link observations based on their vantage point. Imagine a machine on a factory floor it has a reference flow and a collection of child flows that can each be observed rom the machine’s vantage point. Those flows, in turn, imply other nodes, the “partners” to the exchange. The modeler can follow each flow in turn to its partner node, and make a new set of observations.
Each node of the tree can be quantity-conserving, allowing the modeler to enforce physical consistency.
Nodes can be built in small pieces and linked together to implement a variety of design strategies.
[ need a visual ]
Foreground and Background
One purpose of the foreground-background distinction is to leverage the modeler’s perspective to give a clear definition of what has been modeled. Everything the modeler has the capacity to specify becomes part of the foreground by definition.
The flip side of that condition is that the background is immutable. No part of the background should be adjusted by the modeler, because it would then lose its characteristic of being external to the modeling task.
Under that principle, Antelope software is designed to treat all background data resources as authoritative and read-only. If a modeler wishes to make a modification to a background data set, it must be brought into the foreground first. There is a set of foreground modeling tools that facilitates this approach.